GPT-2 124M 빌드·학습을 도와주는 웹 가이드
hibiki는 GPT-2 124M을 처음부터 구현·학습하는 저장소다. Andrej Karpathy의 GPT 재현·토크나이저 강의(Let’s reproduce GPT-2 (124M), Let’s build the GPT Tokenizer) 흐름을 따르며, 학습 스크립트(train_gpt2.py)와 함께 설정·시각화·개념 정리용 웹 UI(web/)를 둔다.
홈 화면
다크 배경에 골드 악센트 버튼, Overview / Build / Visualization / Learn / Attention paper 내비게이션, KO | EN 토글이 한 화면에 모여 있다.
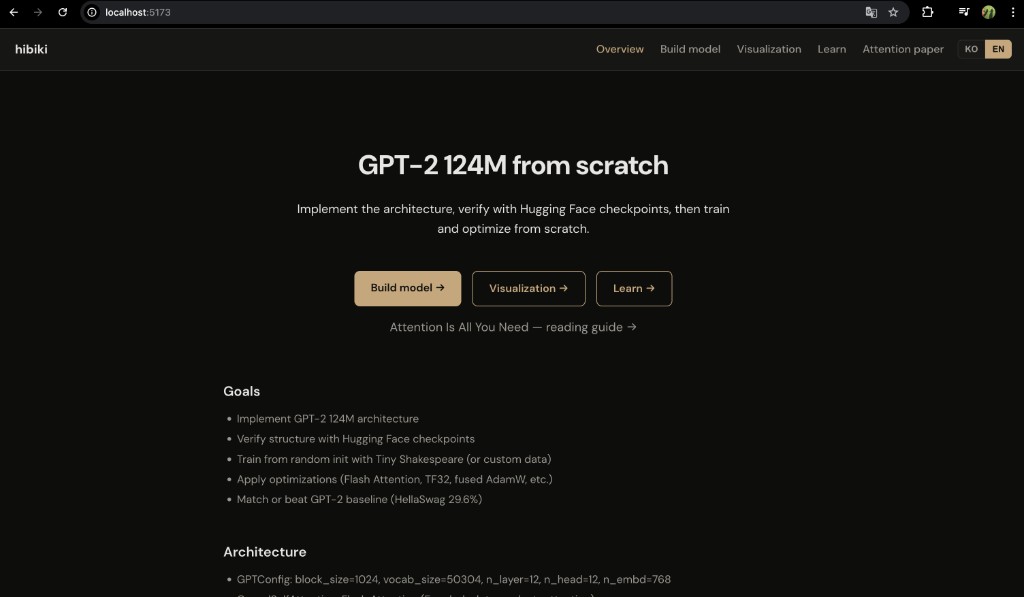
hibiki 웹 UI — 로컬 npm run dev (Vite 기본 포트 5173)
구성
| 경로 | 설명 |
|---|---|
| 프로젝트 루트 | train_gpt2.py, 모델·데이터·학습 로직 (Python 3.10+) |
web/ | Vite + React — 빌드 명령 생성, 파이프라인/아키텍처 시각화, 학습 가이드, Attention 논문 안내 |
Python 환경
pip install -e .
# 선택: Hugging Face 체크포인트 검증 등
pip install -e ".[pretrained]"
학습 예시는 웹 Build model 페이지에서 모드·하이퍼파라미터를 고른 뒤 생성되는 명령을 복사하거나, 저장소의 train_gpt2.py 도움말을 참고하면 된다.
웹 UI (web/)
cd web
npm install
npm run dev
브라우저에서 http://localhost:5173 — 프로덕션 정적 파일은 npm run build 후 web/dist/에 생성된다.
주요 화면
| 경로 | 내용 |
|---|---|
/ | 개요, 아키텍처·최적화 요약, 빠른 시작 |
/build | 학습 모드·하이퍼파라미터 → 터미널에 붙여 넣을 명령 생성 |
/viz | 학습 파이프라인, GPT-2 블록 다이어그램, 핵심 4구성(임베딩·어텐션·MLP·언임베딩), 토큰화(인터랙티브 BPE·YouTube 참고) |
/learn | 구현·학습 개념을 단계별로 정리 |
/attention-is-all-you-need | Attention Is All You Need 요약, KaTeX 수식·SVG 도식, 시각화 탭의 어텐션 그리드로 연결 |
언어 전환은 헤더의 KO / EN 토글이다.
기능 요약 (기존 상세)
- Build: overfit / pretrained / train 모드와 하이퍼파라미터 →
train_gpt2.py용 명령·설명 한 줄씩. - Learn: 1장~8장·부록 형태로 배치, 시퀀스, Pre-LN, 손실, 역전파, AdamW 등.
- Visualization: 파이프라인 카드, 12블록 구조, 토큰화 탭(BPE·encode/decode 다이어그램, 강의 챕터 링크).
기술 스택
- 프론트: React 18, TypeScript, Vite, React Router
- 스타일: CSS 변수, 다크 톤(홈·전역 테마)
- 언어: 자체 i18n(ko/en),
localStorage에 언어 저장
백엔드는 없고 학습은 로컬에서 train_gpt2.py로 실행한다.
개발 메모
web/node_modules는 저장소에 포함하지 않는다. 클론 후cd web && npm install필요..cursorrules에 Pre-LN, weight tying, Flash Attention 등 모델·코딩 가이드가 정리되어 있다.
대상 독자
- GPT-2 124M을 처음부터 구현·학습해 보고 싶은 사람
- 학습률·배치·gradient accumulation을 막 쓰기 시작한 사람
- 빌드 옵션이나 Learn 용어가 낯선 사람
LLM 작동 방식 및 원리
LLM(Large Language Model)은 대량의 텍스트 데이터를 학습하여, 입력된 문맥을 바탕으로 다음에 올 토큰을 예측하는 방식으로 동작한다.
이 과정은 크게 다음 단계로 이해할 수 있다.
Tokenizer → Token Embedding → Positional/Context Encoding → Transformer 연산 → Softmax → Sampling/Decoding
1. Tokenizer
Tokenizer는 자연어 처리 시스템에서 입력 텍스트를 처리하는 첫 번째 단계이다.
사람이 읽는 문장은 그대로는 신경망이 처리할 수 없기 때문에, 먼저 텍스트를 토큰(Token) 이라는 단위로 분할한 뒤, 이를 숫자 ID로 바꾸어 모델에 전달한다.
토큰(Token)이란?
토큰은 텍스트를 구성하는 최소 단위이다. 모델마다 기준이 다를 수 있으며, 다음과 같은 형태가 될 수 있다.
- 하나의 단어
- 단어의 일부 (서브워드)
- 문자 하나
- 공백, 구두점 같은 기호
예를 들어 "나는 밥을 먹었다"라는 문장이 있을 때, 토크나이저는 이를["나는", "밥을", "먹었다"]처럼 나눌 수도 있고, 서브워드 기반이라면 더 잘게 나눌 수도 있다.
왜 토큰화가 필요한가?
신경망은 문자열 자체를 이해하지 못하고 숫자만 처리할 수 있다.
따라서 각 토큰에 고유한 정수 ID를 부여해야 한다.
"나는" → 1523
"밥을" → 8172
"먹었다" → 2941
→ [1523, 8172, 2941]
2. BPE (Byte Pair Encoding)
LLM에서 많이 쓰이는 토크나이저 중 하나가 BPE이다. BPE는 텍스트를 서브워드(subword) 단위로 분리하는 방식이다.
핵심 아이디어
BPE는 처음에는 문자를 기본 단위로 시작한 뒤, 텍스트에서 자주 함께 등장하는 문자 쌍을 반복적으로 병합하여 새로운 단위를 만든다.
"l" + "o" → "lo"
"lo" + "w" → "low"
자주 쓰이는 단어는 통째로 토큰이 되고, 드문 단어는 여러 서브워드로 쪼개어 표현된다.
BPE의 장점
| 장점 | 설명 |
|---|---|
| 희귀 단어 처리 | "unbelievable" → "un" + "believ" + "able" |
| 어휘 집합 크기 절약 | 모든 단어를 사전에 넣지 않아도 됨 |
| 일반화에 유리 | 새로운 단어도 기존 서브워드 조합으로 대응 가능 |
3. Token Embedding
토큰화가 끝나면 각 토큰은 단순한 정수 ID 상태이다. 숫자 ID 자체는 의미를 담고 있지 않으므로, LLM은 각 토큰 ID를 고정 길이의 실수 벡터로 바꾼다. 이것이 Token Embedding이다.
"나는" → [0.12, -0.08, 0.31, ...]
"밥을" → [0.45, 0.02, -0.19, ...]
"먹었다" → [0.28, 0.61, -0.07, ...]
이 벡터들은 모델이 학습 과정에서 자동으로 조정한 값들이다.
임베딩의 특징
- 의미적 유사성 반영: 비슷한 의미의 단어는 벡터 공간에서도 가까운 위치에 놓인다 (
"왕"↔"여왕","고양이"↔"강아지") - 계산 효율성: 벡터 형태이면 GPU/TPU를 통한 대규모 병렬 연산이 가능하다
- 출발점: Transformer는 이 임베딩 벡터를 바탕으로 이후 문맥 처리를 진행한다
초기 임베딩은 문맥을 완전히 반영하지 않는다. 문맥은 이후 Transformer 층을 거치면서 반영된다.
4. Encoding: 위치와 문맥 반영
토큰 임베딩만으로는 문장의 순서를 알 수 없다."고양이가 사람을 물었다"와 "사람이 고양이를 물었다"는 단어는 비슷하지만 의미는 전혀 다르다.
4-1. 위치 정보 반영 (Positional Encoding)
Transformer는 RNN과 달리 순서를 자동으로 기억하지 못하므로, 각 토큰이 문장 내 몇 번째 위치에 있는지 알려줘야 한다.
모델 입력 = Token Embedding + Position Embedding
4-2. 문맥 정보 반영 (Self-Attention)
입력 벡터들은 Transformer 내부에서 self-attention 연산을 거치며, 각 토큰이 다른 토큰들과의 관계를 참고해 문맥이 반영된 표현으로 업데이트된다.
예를 들어 "bank"라는 단어는
"river bank"→ 강둑"go to the bank"→ 은행
초기 토큰 임베딩은 같을 수 있지만, 문맥을 본 뒤에는 서로 다른 표현으로 바뀐다.
5. Token Embedding과 Encoding의 관계
| 단계 | 역할 |
|---|---|
| Token Embedding | 각 토큰을 벡터로 바꾸는 단계. "먹었다" 토큰 자체의 기본 표현 |
| Encoding | 그 벡터가 문장 전체 속에서 어떤 의미를 가지는지 반영. 위치·문맥 포함 |
Token Embedding = 단어의 기본 의미
Encoding = 문장 속 문맥과 위치를 반영한 의미
6. Transformer에서 실제로 일어나는 일
LLM의 핵심은 Transformer 구조다. 입력 토큰 벡터들은 여러 개의 Transformer 블록을 통과하면서 점점 더 정교한 표현으로 바뀐다.
6-1. Self-Attention
각 토큰이 다른 토큰들을 얼마나 참고해야 하는지를 계산한다. 주어와 동사, 지시어와 대상어 같은 관계를 파악하는 데 핵심이다.
6-2. Feed Forward Network
Attention을 통해 섞인 정보를 각 토큰별로 더 복잡하게 변환한다.
6-3. Residual Connection과 Layer Normalization
학습 안정성과 정보 보존을 위해 사용된다.
결과적으로 각 토큰은 단순한 단어 벡터가 아니라, 문맥 전체를 반영한 고차원 표현이 된다.
7. Softmax: 다음 토큰 확률 만들기
모델은 현재까지의 문맥을 바탕으로, 다음에 어떤 토큰이 올지를 예측해야 한다.
마지막 층에서는 각 어휘(vocabulary)에 대해 하나의 점수를 출력하는데, 이 점수를 logit(로짓) 이라고 한다.
"나는" → 1.2
"밥을" → 2.8
"학교에" → 0.5
이 값들은 아직 확률이 아니다. 이 점수들을 확률로 바꾸는 함수가 Softmax이다.
$$p_j = \frac{e^{z_j}}{\sum_{k=1}^{K} e^{z_k}}$$
- $K$: 전체 어휘 수
- $z_j$: $j$번째 토큰의 logit
- $p_j$: $j$번째 토큰이 선택될 확률
Softmax를 쓰는 이유
| 이유 | 설명 |
|---|---|
| 확률 해석 가능 | 출력값을 0~1 사이로 만들고 합을 1로 정규화 |
| 선호도 강조 | 지수함수로 높은 점수를 더 두드러지게 만듦 |
| 학습에 적합 | 미분 가능하여 역전파에 활용 가능 |
8. LLM에서의 Softmax 예시
문장이 "나는 밥을"까지 주어졌다고 하자.
logit: "먹었다" 4.2 / "좋아한다" 2.1 / "학교에" 0.3
softmax: "먹었다" 0.80 / "좋아한다" 0.17 / "학교에" 0.03
모델은 다음 토큰으로 "먹었다"를 가장 유력하게 본다.
Softmax는 분류 문제에서도 동일하게 쓰인다.
아이리스 분류 3클래스라면z=[2.0, 1.0, 0.1]→[0.66, 0.24, 0.10].
LLM은 수만 개의 vocabulary 중 하나를 고르는 것이 다를 뿐, 원리는 같다.
9. 학습 시 오차 계산: Cross-Entropy
모델은 정답 토큰과 비교하여 오차를 계산하고, 이를 줄이도록 학습한다.
이때 사용하는 손실 함수가 Cross-Entropy이다.
예시:
- 모델 예측:
[0.26, 0.70, 0.04] - 정답 (두 번째 클래스):
[0, 1, 0]
Cross-Entropy는 정답 클래스의 확률이 높을수록 작아지고, 낮을수록 커진다.
모델은 정답 토큰에 더 높은 확률을 주는 방향으로 학습된다.
10. Sampling: 다음 토큰 선택
Softmax로 확률 분포가 만들어졌다고 해서, 항상 가장 높은 확률의 토큰만 고르지는 않는다.
| 전략 | 설명 | 장점 | 단점 |
|---|---|---|---|
| Greedy Decoding | 가장 확률 높은 토큰 선택 | 일관적·안정적 | 반복적·단조로움 |
| Random Sampling | 확률 분포로 무작위 선택 | 다양한 문장 생성 | 품질 불안정 |
| Top-k Sampling | 상위 k개 후보 안에서 샘플링 | 균형 있는 다양성 | k 설정 필요 |
| Top-p (Nucleus) | 누적 확률 p까지의 후보 안에서 샘플링 | 동적 후보 조절 | p 설정 필요 |
| Temperature | logit 스케일 조정으로 분포 날카로움 제어 | 창의성 조절 가능 | 극단값 위험 |
11. Decoding: 토큰을 다시 텍스트로
모델이 출력한 토큰 ID 시퀀스를 다시 자연어 문장으로 바꾸는 과정이다.
[1523, 8172, 2941] → "나는 밥을 먹었다"
- Tokenizer: 텍스트 → 토큰 ID
- Decoder: 토큰 ID → 자연어 문자열
12. 전체 과정 요약
| 단계 | 설명 |
|---|---|
| ① 토큰화 | 텍스트를 토큰으로 분할, 각 토큰을 ID로 변환 |
| ② Token Embedding | 각 토큰 ID를 고차원 벡터로 변환 |
| ③ 위치 정보 추가 | 각 토큰의 순서 정보를 반영 |
| ④ Transformer 연산 | Self-attention + FFN으로 문맥 반영 표현 생성 |
| ⑤ Logit 출력 | 다음 토큰 후보 전체에 대해 점수 계산 |
| ⑥ Softmax 적용 | 점수를 확률 분포로 변환 |
| ⑦ Sampling | 확률 분포를 바탕으로 다음 토큰 선택 |
| ⑧ Decoding | 선택된 토큰들을 자연어 텍스트로 변환 |
이 과정을 반복하면서 문장을 한 토큰씩 생성한다.
저장소·참고
참고 영상
Karpathy 강의와 hibiki 흐름을 같이 보면 이해가 빠르다.
Let’s reproduce GPT-2 (124M) — YouTube
Let’s build the GPT Tokenizer — YouTube
명령어나 개념이 부담되면 Build → Learn → Visualization 순으로 hibiki 웹을 따라가 보길 권한다. 팀과 공유할 때는 한·영 토글로 맞춰 두면 된다.