Discord 멀티 에이전트 시스템 구축 노트
Mac 기반 Discord-Centered Multi-Agent Setup
단순 챗봇 데모에서 한 단계 더 가고 싶었다. 몇 개의 역할형 에이전트로 작업을 라우팅하고, 스스로 상태를 관측하고, 실제로 쓰는 채널로 알림을 보내는 작은 시스템을 만들고 싶었다.
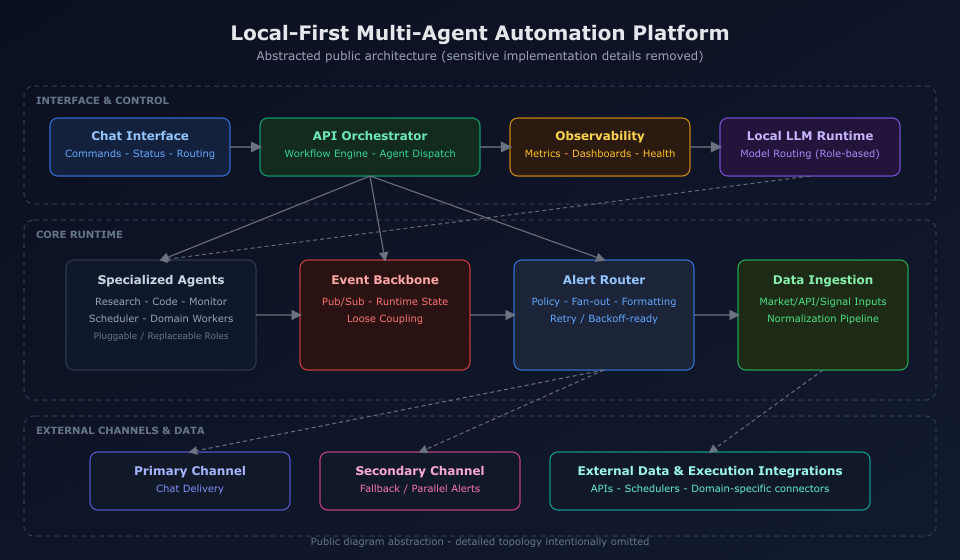
결과물은 Mac에서 동작하는 Discord 전면형 멀티 에이전트 구성이다. FastAPI 오케스트레이터가 라우팅을 담당하고, Redis가 이벤트를 전달하며, Ollama가 모델을 로컬에서 서빙한다.
왜 만들었나
아래 문제가 반복됐다.
- 채팅, 스크립트, 대시보드로 워크플로가 흩어짐
- 역할별 에이전트를 한 곳에서 호출하기 어려움
- 야간 장시간 실행 시 알림 누락 발생
- 실행 중 시스템이 건강한지 판단하기 어려움
그래서 하나의 스택으로 정리했다.
- Discord를 제어면으로 사용
- FastAPI를 오케스트레이터로 사용
- Redis pub/sub를 이벤트 백본으로 사용
- Ollama를 로컬 모델 서빙 계층으로 사용
- Prometheus + Grafana를 가시성 계층으로 사용
구성 요소
각 구성은 의도적으로 작고 분리되어 있다.
- Discord Bot - 채널 기반 라우팅, 슬래시 커맨드, 상태 UX
- Orchestrator (FastAPI) - 에이전트 선택, 실행, 히스토리 관리
- Agents - orchestrator, stock, research, code, scheduler, system monitor
- Redis - pub/sub와 최소 세션 상태 저장
- Observability - Prometheus 메트릭, Grafana 대시보드
- Ollama -
MODEL_*환경변수 매핑으로 역할별 모델 지정
결과적으로 Discord는 채팅 앱이 아니라 실행 중인 스택을 다루는 콘솔처럼 동작한다.
요청 처리 흐름
대부분의 에이전트는 같은 패턴을 따른다.
- Discord 채널 메시지 또는 슬래시 커맨드가 들어온다.
- Bot이 채널/명령 기준으로 에이전트 타입을 결정한다.
- Orchestrator가 해당 에이전트를 실행하거나 필요 시 병렬 fan-out 한다.
- 에이전트는 결과를 반환하고, 주의가 필요한 경우 이벤트를 발행한다.
- Redis가 이벤트를 브로드캐스트한다.
- 리스너가 Discord(선택적으로 Kakao 개인 채널 포함)로 전달한다.
- Prometheus가 요청 수와 지연 메트릭을 수집한다.
로컬 모델을 선택한 이유
추론을 로컬에 둔 건 실무적인 이유가 컸다.
- Ollama가 Mac에서 네이티브로 실행되어 Metal GPU를 사용함
.env의 역할별 모델(MODEL_ORCHESTRATOR,MODEL_CODE등)로 무거운 작업/빠른 작업을 분리 가능- 프롬프트와 컨텍스트가 외부로 나가지 않음
- API 비용이 예측 가능함
그래서 이건 “Discord bot"이라기보다 “스택"에 가깝다. 그리고 잠시 뒤에 말하겠지만, 이 점이 구성 전체를 로컬 중심으로 유지하게 만든다.
최근 변경 사항
자유 텍스트 메모를 구조화 스키마로 전환. 도메인 메모 일부를 코드 레벨 데이터 구조와 포맷터로 바꿔 분석/요약/알림이 같은 소스를 읽게 했다.
Kakao 알림 포팅. 이전 프로젝트에서 검증한 Kakao 전송 흐름(개인/워크스페이스 모드, 장문 분할, 토큰 갱신)을 Discord 경로 옆에 붙였다. 기존 Discord 동작은 유지했다.
코드 에이전트 모델 업데이트. Env 기본값, pull 스크립트, 아키텍처 다이어그램을 최신 Gemma 기준으로 다시 맞췄다.
이 프로젝트의 본질
주식 에이전트는 이 배관을 통과하는 하나의 경로일 뿐 핵심이 아니다. 핵심은 재사용 가능한 기반이다: 에이전트 라우팅, 이벤트 백본, 로컬 모델 운영, 기본 모니터링, 플러그형 알림 구조. 새로운 유스케이스는 별도 스크립트가 아니라 새 에이전트를 추가하는 방식으로 붙는다.
실제 버전을 로컬에 두는 이유
글을 정리하면서 계속 떠오른 점이 하나 있다. AI가 개입된 지금, 공개된 구성은 아주 짧은 시간 안에 복제된다. GitHub나 블로그에 올린 아키텍처는, 읽는 시점에는 내가 로컬에서 실제로 돌리는 최신 상태보다 이미 한 단계 뒤일 가능성이 높다. 과장이 아니라, LLM이 공개 구조를 반나절 내에 재구성할 수 있는 시대의 기본값에 가깝다.
그래서 공개 기준을 두 단계로 나눴다. 구조와 반복 가능한 기본 뼈대는 공유한다. 반대로 도메인 로직, 파라미터 선택, 프롬프트 스캐폴딩은 로컬에 둔다. 이 관점에서 로컬 모델 선택은 취향이 아니라 합리적인 기본값이다. 실제 경쟁력은 실행 중인 버전에 있고, 그 반복 루프를 내 환경 안에서 돌리는 편이 비용/속도/통제 측면에서 유리하기 때문이다.
미래의 나에게
- 모델보다 신뢰성 작업이 훨씬 오래 걸렸다.
- 구조화된 포맷은 두 번째 소비자가 붙는 순간 바로 이득이 났다.
- pub/sub 덕분에 신규 기능이 기존 기능과 덜 엉켰다.
- 단일 채널보다 이중 알림 경로가 운영 리스크를 크게 줄인다.
- 메트릭은 초기에 넣는 비용이 작고, 나중에 붙이는 비용이 크다.
결론적으로 이번 빌드는 먼저 플랫폼을 안정적이고 확장 가능하게 만드는 작업이었다. 공개할 가치가 있는 부분은 그 기반이며, 실제 투자 로직은 그 위에서 로컬로 계속 발전한다.