A Discord Multi-Agent System: Notes on the Build
Discord-Centered Multi-Agent Setup on a Mac
I wanted something a step beyond a chatbot demo - a small system that could route work to a few specialized agents, watch itself, and push alerts to the channels I actually use.
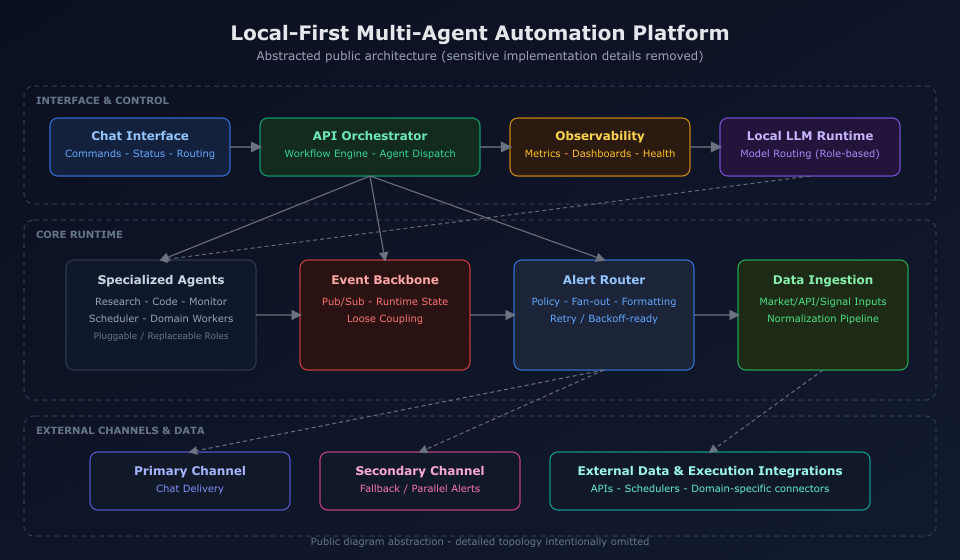
What I ended up with is a Discord-fronted multi-agent setup running on a Mac. A FastAPI orchestrator handles routing, Redis carries events, and Ollama serves the models locally.
Why I Built It
A few things kept getting in the way:
- workflows scattered across chat, scripts, and dashboards
- no single place to invoke different agent roles
- alert delivery dropped messages when I left things running overnight
- hard to tell, mid-run, whether anything was actually healthy
So I pulled it into one stack:
- Discord as the control surface
- FastAPI as the orchestrator
- Redis pub/sub for events
- Ollama for local model serving
- Prometheus + Grafana for visibility
What’s In It
The pieces are deliberately small:
- Discord Bot - channel-based routing, slash commands, status UX
- Orchestrator (FastAPI) - picks an agent, runs it, keeps history
- Agents - orchestrator, stock, research, code, scheduler, system monitor
- Redis - pub/sub plus a bit of session state
- Observability - Prometheus metrics, Grafana dashboards
- Ollama - one model per agent role via
MODEL_*env mapping
The effect is that Discord behaves more like a console for the running stack than a chat app.
How a Request Flows
The pattern is the same across most agents:
- A message lands in a Discord channel or slash command.
- The bot picks the agent type from the channel/command.
- The orchestrator runs that agent, or fans out to several in parallel.
- Each agent returns a result and, if something deserves attention, emits an event.
- Redis broadcasts the event.
- Listeners deliver it to Discord (and optionally Kakao for personal channels).
- Prometheus collects request and timing metrics throughout.
Local Models, On Purpose
Inference stays local for a handful of practical reasons:
- Ollama runs natively on the Mac so it can use the Metal GPU.
- Each agent has its own model in
.env(MODEL_ORCHESTRATOR,MODEL_CODE, etc.), so heavier roles can pick a bigger model and faster roles a lighter one. - Prompts and context never leave the box.
- No surprise API bills.
That’s the main reason this is “the stack” rather than “a Discord bot” - and, as I’ll get to in a moment, the reason it stays mostly local.
Recent Changes
Structured schemas instead of free-text notes. I rewrote a chunk of the domain notes as code-level data structures with formatters, so analysis, summaries, and notifications all read from the same source.
Kakao notifications, ported in. I lifted the Kakao notification flow from an earlier project - personal vs. workspace delivery, long-message chunking, token refresh - and slotted it next to the existing Discord path. Discord behavior didn’t change.
Code agent model bumped to the current Gemma. Env defaults, the pull script, and the architecture diagram are all back in sync.
What It Actually Is
The stock agent is one route through the plumbing, not the point of the project. What I’m really after is a small, reusable base for this kind of work: agent routing, an event backbone, local models, basic monitoring, and pluggable notifications. New use cases drop in as another agent rather than another standalone script.
Why the Real Version Stays Local
One thing kept surfacing while I was writing this up. With AI in the loop, any published configuration gets copied in very little time. An architecture posted on GitHub or in a blog is, by the time you read it, probably already a step behind whatever I’m actually running locally. That isn’t an exaggeration - it’s close to the default in an era when an LLM can reconstruct a public structure in half a day.
So I’ve split what I publish into two tiers. The structure and the repeatable scaffolding go out. Domain logic, parameter choices, and prompt scaffolding stay local. From that angle, choosing local models stops being a preference and becomes the sensible default: the real edge lives in the running version, and keeping that iteration loop inside my own environment is the better deal on cost, speed, and control.
What I’d Tell Future Me
- Reliability work took more time than the model work, by a lot.
- Structured data formats paid off the moment a second consumer showed up.
- Pub/sub kept new features from tangling into existing ones.
- Two notification paths feel a lot less risky than one.
- Adding metrics up front is cheap; bolting them on later is not.
The build itself was about getting the platform stable and extensible first - the part that’s worth publishing. The actual investment logic lives on top, and stays where it runs.